第二代DNA测序技术(运用边合成边测序原理的技术)

第二代DNA测序技术又称下一代测序技术,是对第一代测序技术的划时代变革的核心。现有的技术平台主要包括Roche/454 GS FLX、Illumina/Sol-exa GenomeAnalyzer、Helicos BioSciences公司的HeliScope™ Single Molecule Sequencer、美国Dana-her Motion公司推出的Polonator;以及连接法测序 (sequencing by ligation),即通过引物来定位核酸信息,技术平台有Applied Biosystems/SOLiD™ system。
第二代DNA测序技术
Next-generation sequencing
Roche/454 GS FLX、
基本介绍
1.概述
DNA测序(DNA sequencing)作为一种重要的实验技术,在生物学研究中有着广泛的应用。早在DNA双螺旋结构(Watson and Crick,1953)被发现后不久就有人报道过DNA测序技术,但是当时的操作流程复杂,没能形成规模。随后在1977年Sanger发明了具有里程碑意义的末端终止测序法,同年A.M.Maxam和W.Gilbert发明了化学降解法。Sanger法因为既简便又快速,并经过后续的不断改良,成为了迄今为止DNA测序的主流。然而随着科学的发展,传统的Sanger测序已经不能完全满足研究的需要,对模式生物进行基因组重测序以及对一些非模式生物的基因组测序,都需要费用更低、通量更高、速度更快的测序技术,第二代测序技术(Next-generation sequencing)应运而生。第二代测序技术的核心思想是边合成边测序[1](Sequencing by Synthesis),即通过捕捉新合成的末端的标记来确定DNA的序列,现有的技术平台主要包括Roche/454 FLX、Illumina/Solexa genome Analyzer和Applied Biosystems SOLID system。这三个技术平台各有优点,454 FLX的测序片段比较长,高质量的读长(read)能达到400bp;Solexa测序性价比最高,不仅机器的售价比其他两种低,而且运行成本也低,在数据量相同的情况下,成本只有454测序的1/10;SOLID测序的准确度高,原始碱基数据的准确度大于99.94%,而在15X覆盖率时的准确度可以达到99.999%,是目前第二代测序技术中准确度最高的。虽然第二代测序技术的工作一般都由专业的商业公司来完成,但是了解测序原理、操作流程等会对后续的数据分析有很重要的作用,下文将以Illumina/Solexa Genome Analyzer 测序为例,简述第二代测序技术的基本原理、操作流程等方面。
2.基本原理
Illumina/Solexa Genome Analyzer测序的基本原理是边合成边测序。在Sanger等测序方法的基础上,通过技术创新,用不同颜色的荧光标记四种不同的dNTP,当DNA聚合酶合成互补链时,每添加一种dNTP就会释放出不同的荧光,根据捕捉的荧光信号并经过特定的计算机软件处理,从而获得待测DNA的序列信息。
3.操作流程
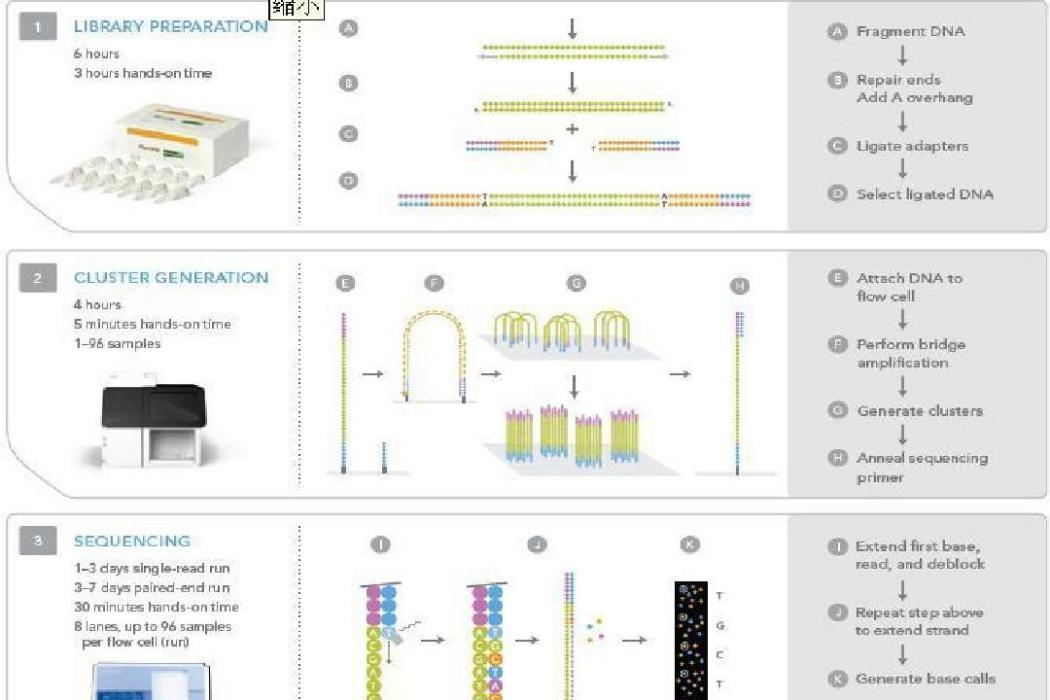
1)测序文库的构建(Library Construction)
首先准备基因组DNA(虽然测序公司要求样品量要达到200ng,但是Gnome Analyzer系统所需的样品量可低至100ng,能应用在很多样品有限的实验中),然后将DNA随机片段化成几百碱基或更短的小片段,并在两头加上特定的接头(Adaptor)。如果是转录组测序,则文库的构建要相对麻烦些,RNA片段化之后需反转成cDNA,然后加上接头,或者先将RNA反转成cDNA,然后再片段化并加上接头。片段的大小(Insert size)对于后面的数据分析有影响,可根据需要来选择。对于基因组测序来说,通常会选择几种不同的insert size,以便在组装(Assembly)的时候获得更多的信息。
2)锚定桥接(Surface Attachment and Bridge Amplification)
Solexa测序的反应在叫做flow cell的玻璃管中进行,flow cell又被细分成8个Lane,每个Lane的内表面有无数的被固定的单链接头。上述步骤得到的带接头的DNA 片段变性成单链后与测序通道上的接头引物结合形成桥状结构,以供后续的预扩增使用。
3)预扩增(Denaturation and Complete Amplification)
添加未标记的dNTP 和普通Taq 酶进行固相桥式PCR 扩增,单链桥型待测片段被扩增成为双链桥型片段。通过变性,释放出互补的单链,锚定到附近的固相表面。通过不断循环,将会在Flow cell 的固相表面上获得上百万条成簇分布的双链待测片段。
4)单碱基延伸测序(Single Base Extension and Sequencing)
在测序的flow cell中加入四种荧光标记的dNTP 、DNA 聚合酶以及接头引物进行扩增,在每一个测序簇延伸互补链时,每加入一个被荧光标记的dNTP就能释放出相对应的荧光,测序仪通过捕获荧光信号,并通过计算机软件将光信号转化为测序峰,从而获得待测片段的序列信息。从荧光信号获取待测片段的序列信息的过程叫做Base Calling,Illumina公司Base Calling所用的软件是Illumina’s Genome Analyzer Sequencing Control Software and Pipeline Analysis Software。读长会受到多个引起信号衰减的因素所影响,如荧光标记的不完全切割。随着读长的增加,错误率也会随之上升。
5)数据分析(Data Analyzing)
这一步严格来讲不能算作测序操作流程的一部分,但是只有通过这一步前面的工作才显得有意义。测序得到的原始数据是长度只有几十个碱基的序列,要通过生物信息学工具将这些短的序列组装成长的Contigs甚至是整个基因组的框架,或者把这些序列比对到已有的基因组或者相近物种基因组序列上,并进一步分析得到有生物学意义的结果。
1.边合成边测序 · 边合成边测序技术的相关参考(引用日期:2016-11-14)